GENETICS AND BIOINFORMATICS
In this issue of the newsletter, we highlight the research being carried out at the Department of Genetics and Bioinformatics, led by Prof. Fahd Al-Mulla, at DDI.
Research Update
Research at the department is aided by two components
Published on 01/08/2019
Research at the department is aided by two components – one with bioinformatics capabilities and the other with experimental genetics expertise. The core capabilities of the Bioinformatics component of the department include analysis of genome data (the hereditary information encoded in an organism’s DNA) obtained from technologies such as Next Generation Sequencing (NGS), a revolutionary technique which can sequence an organism’s whole DNA (i.e. it’s whole genome) in a single day. Furthermore, the whole exome (corresponding to the genome region that codes for around 18,000 genes and proteins) could also be sequenced; the exome region accounts for ~1% of the genome and is the blueprint for an organism’s protein-producing machinery. This analysis assists scientists in further understanding the underlying genetic causes of obesity, diabetes and related disorders.
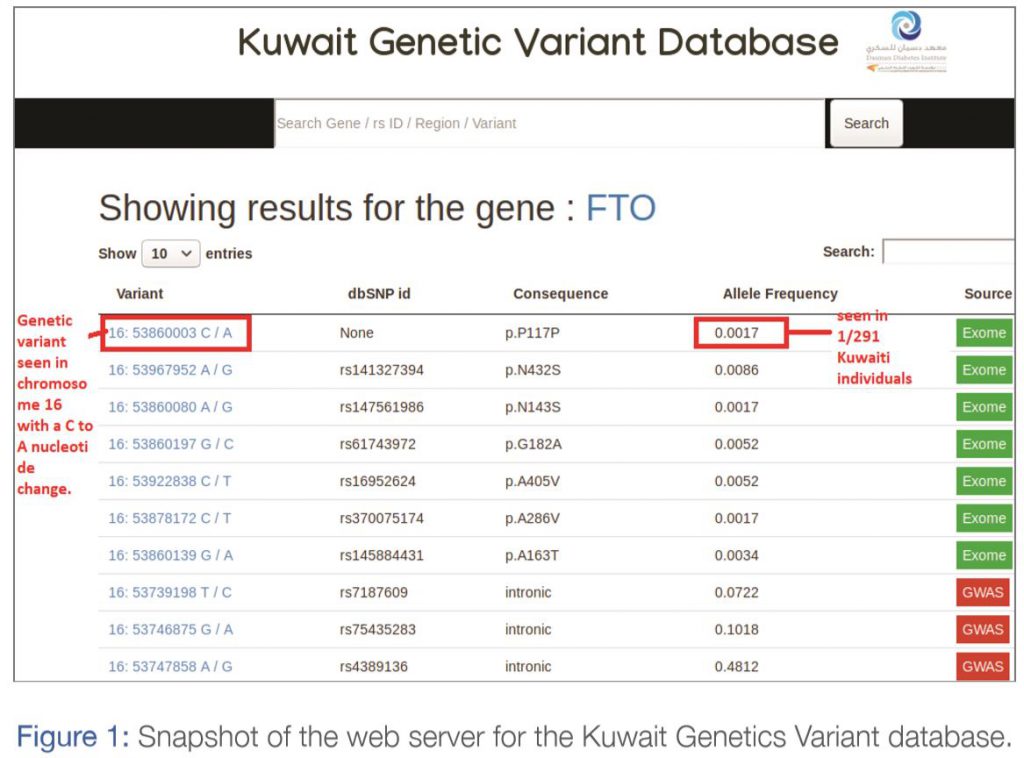
Their expertise also lies in handling databases, software and writing custom software code for handling large-scale genetics data. The team has made substantial contributions in discovering the genetic structure of the Kuwaiti population and genetic risk factors for diabetes and related disorders. In addition, the team has created a database of genetic variants (i.e. the genetic differences amongst individuals) in the Kuwaiti population (Figure 1). The team participates in international consortiums, such as Genetic Investigation of Anthropometric Traits (GIANT) and Global Lipids Genetics Consortium (GLGC), to share and maximize use of genomics data in the search for risk genes in diabetes.